![]()
Updated Mar 22, 2026 Test Engine to Practice Test for Databricks-Generative-AI-Engineer-Associate Valid and Updated Dumps
Exam Questions for Databricks-Generative-AI-Engineer-Associate Updated Versions With Test Engine
NEW QUESTION # 22
A Generative Al Engineer is deciding between using LSH (Locality Sensitive Hashing) and HNSW (Hierarchical Navigable Small World) for indexing their vector database Their top priority is semantic accuracy Which approach should the Generative Al Engineer use to evaluate these two techniques?
- A. Compare the Recall-Onented-Understudy for Gistmg Evaluation (ROUGE) scores of returned results for a representative sample of test inputs
- B. Compare the Levenshtein distances of returned results against a representative sample of test inputs
- C. Compare the Bilingual Evaluation Understudy (BLEU) scores of returned results for a representative sample of test inputs
- D. Compare the cosine similarities of the embeddings of returned results against those of a representative sample of test inputs
Answer: D
Explanation:
The task is to choose between LSH and HNSW for a vector database index, prioritizing semantic accuracy. The evaluation must assess how well each method retrieves semantically relevant results. Let's evaluate the options.
Option A: Compare the cosine similarities of the embeddings of returned results against those of a representative sample of test inputs Cosine similarity measures semantic closeness between vectors, directly assessing retrieval accuracy in a vector database. Comparing returned results' embeddings to test inputs' embeddings evaluates how well LSH or HNSW preserves semantic relationships, aligning with the priority.
Databricks Reference: "Cosine similarity is a standard metric for evaluating vector search accuracy" ("Databricks Vector Search Documentation," 2023).
Option B: Compare the Bilingual Evaluation Understudy (BLEU) scores of returned results for a representative sample of test inputs BLEU evaluates text generation (e.g., translations), not vector retrieval accuracy. It's irrelevant for indexing performance.
Databricks Reference: "BLEU applies to generative tasks, not retrieval" ("Generative AI Cookbook").
Option C: Compare the Recall-Oriented-Understudy for Gisting Evaluation (ROUGE) scores of returned results for a representative sample of test inputs ROUGE is for summarization evaluation, not vector search. It doesn't measure semantic accuracy in retrieval.
Databricks Reference: "ROUGE is unsuited for vector database evaluation" ("Building LLM Applications with Databricks").
Option D: Compare the Levenshtein distances of returned results against a representative sample of test inputs Levenshtein distance measures string edit distance, not semantic similarity in embeddings. It's inappropriate for vector-based retrieval.
Databricks Reference: No specific support for Levenshtein in vector search contexts.
Conclusion: Option A (cosine similarity) is the correct approach, directly evaluating semantic accuracy in vector retrieval, as recommended by Databricks for Vector Search assessments.
NEW QUESTION # 23
A Generative AI Engineer is designing a chatbot for a gaming company that aims to engage users on its platform while its users play online video games.
Which metric would help them increase user engagement and retention for their platform?
- A. Diversity of responses
- B. Lack of relevance
- C. Randomness
- D. Repetition of responses
Answer: A
Explanation:
In the context of designing a chatbot to engage users on a gaming platform, diversity of responses (option B) is a key metric to increase user engagement and retention. Here's why:
Diverse and Engaging Interactions:
A chatbot that provides varied and interesting responses will keep users engaged, especially in an interactive environment like a gaming platform. Gamers typically enjoy dynamic and evolving conversations, and diversity of responses helps prevent monotony, encouraging users to interact more frequently with the bot.
Increasing Retention:
By offering different types of responses to similar queries, the chatbot can create a sense of novelty and excitement, which enhances the user's experience and makes them more likely to return to the platform.
Why Other Options Are Less Effective:
A (Randomness): Random responses can be confusing or irrelevant, leading to frustration and reducing engagement.
C (Lack of Relevance): If responses are not relevant to the user's queries, this will degrade the user experience and lead to disengagement.
D (Repetition of Responses): Repetitive responses can quickly bore users, making the chatbot feel uninteresting and reducing the likelihood of continued interaction.
Thus, diversity of responses (option B) is the most effective way to keep users engaged and retain them on the platform.
NEW QUESTION # 24
A Generative Al Engineer would like an LLM to generate formatted JSON from emails. This will require parsing and extracting the following information: order ID, date, and sender email. Here's a sample email:
They will need to write a prompt that will extract the relevant information in JSON format with the highest level of output accuracy.
Which prompt will do that?
- A. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
- B. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
- C. You will receive customer emails and need to extract date, sender email, and order ID. You should return the date, sender email, and order ID information in JSON format.
- D. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Here's an example: {"date": "April 16, 2024", "sender_email": "[email protected]", "order_id":
"RE987D"}
Answer: D
Explanation:
Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM' s responses.
Explanation of Options:
* Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
* Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
* Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
* Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore,Option Bis optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
NEW QUESTION # 25
A Generative Al Engineer is building a system which will answer questions on latest stock news articles.
Which will NOT help with ensuring the outputs are relevant to financial news?
- A. Increase the compute to improve processing speed of questions to allow greater relevancy analysis C Implement a profanity filter to screen out offensive language
- B. Incorporate manual reviews to correct any problematic outputs prior to sending to the users
- C. Implement a comprehensive guardrail framework that includes policies for content filters tailored to the finance sector.
Answer: A
Explanation:
In the context of ensuring that outputs are relevant to financial news, increasing compute power (option B) does not directly improve therelevanceof the LLM-generated outputs. Here's why:
* Compute Power and Relevancy:Increasing compute power can help the model process inputs faster, but it does not inherentlyimprove therelevanceof the answers. Relevancy depends on the data sources, the retrieval method, and the filtering mechanisms in place, not on how quickly the model processes the query.
* What Actually Helps with Relevance:Other methods, like content filtering, guardrails, or manual review, can directly impact the relevance of the model's responses by ensuring the model focuses on pertinent financial content. These methods help tailor the LLM's responses to the financial domain and avoid irrelevant or harmful outputs.
* Why Other Options Are More Relevant:
* A (Comprehensive Guardrail Framework): This will ensure that the model avoids generating content that is irrelevant or inappropriate in the finance sector.
* C (Profanity Filter): While not directly related to financial relevancy, ensuring the output is clean and professional is still important in maintaining the quality of responses.
* D (Manual Review): Incorporating human oversight to catch and correct issues with the LLM's output ensures the final answers are aligned with financial content expectations.
Thus, increasing compute power does not help with ensuring the outputs are more relevant to financial news, making option B the correct answer.
NEW QUESTION # 26
A Generative AI Engineer is using LangGraph to define multiple tools in a single agentic application. They want to enable the main orchestrator LLM to decide on its own which tools are most appropriate to call for a given prompt. To do this, they must determine the general flow of the code. Which sequence will do this?
- A. 1. Define the tools 2. Load each tool into a separate agent 3. Instruct the LLM to use ReAct to call the appropriate agent
- B. 1. Define or import the tools 2. Define the agent 3. Initialize the agent with ReAct, the LLM, and the tools
- C. 1. Define the tools inside the agents 2. Load the agents into the LLM 3. Instruct the LLM to use COT reasoning to determine the appropriate agent
- D. 1. Define or import the tools 2. Add tools and LLM to the agent 3. Create the ReAct agent
Answer: B
Explanation:
In modern agentic frameworks like LangGraph or LangChain, the standard workflow for creating an autonomous tool-calling agent follows a specific sequence. First, tools must be defined (often as Python functions with clear docstrings, which the LLM uses to understand the tool's purpose). Second, the agent logic is defined, which specifies how the LLM should think. Third, the agent is initialized using a logic pattern like ReAct (Reason + Act). The ReAct framework is essential here because it enables the "orchestrator" loop: the LLM receives a prompt, generates a "Thought" about which tool to use, generates an "Action" to call that tool, receives an "Observation" (the tool's output), and repeats until it can provide a final answer. Loading tools into "separate agents" (C) or defining tools "inside" agents (D) are non-standard patterns that add unnecessary complexity and do not align with the centralized orchestration model required for LangGraph.
NEW QUESTION # 27
A Generative Al Engineer is deciding between using LSH (Locality Sensitive Hashing) and HNSW (Hierarchical Navigable Small World) for indexing their vector database Their top priority is semantic accuracy Which approach should the Generative Al Engineer use to evaluate these two techniques?
- A. Compare the Recall-Onented-Understudy for Gistmg Evaluation (ROUGE) scores of returned results for a representative sample of test inputs
- B. Compare the Levenshtein distances of returned results against a representative sample of test inputs
- C. Compare the Bilingual Evaluation Understudy (BLEU) scores of returned results for a representative sample of test inputs
- D. Compare the cosine similarities of the embeddings of returned results against those of a representative sample of test inputs
Answer: D
NEW QUESTION # 28
A Generative Al Engineer is creating an LLM-based application. The documents for its retriever have been chunked to a maximum of 512 tokens each. The Generative Al Engineer knows that cost and latency are more important than quality for this application. They have several context length levels to choose from.
Which will fulfill their need?
- A. context length 2048: smallest model is 11GB and embedding dimension 2560
- B. context length 512: smallest model is 0.13GB and embedding dimension 384
- C. context length 32768: smallest model is 14GB and embedding dimension 4096
- D. context length 514; smallest model is 0.44GB and embedding dimension 768
Answer: B
Explanation:
When prioritizing cost and latency over quality in a Large Language Model (LLM)-based application, it is crucial to select a configuration that minimizes both computational resources and latency while still providing reasonable performance. Here's whyDis the best choice:
* Context length: The context length of 512 tokens aligns with the chunk size used for the documents (maximum of 512 tokens per chunk). This is sufficient for capturing the needed information and generating responses without unnecessary overhead.
* Smallest model size: The model with a size of 0.13GB is significantly smaller than the other options.
This small footprint ensures faster inference times and lower memory usage, which directly reduces both latency and cost.
* Embedding dimension: While the embedding dimension of 384 is smaller than the other options, it is still adequate for tasks where cost and speed are more important than precision and depth of understanding.
This setup achieves the desired balance between cost-efficiency and reasonable performance in a latency- sensitive, cost-conscious application.
NEW QUESTION # 29
A Generative AI Engineer I using the code below to test setting up a vector store: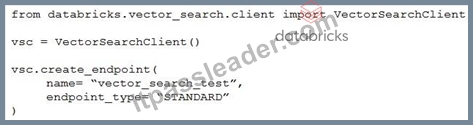
Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
- A. vsc.create_delta_sync_index()
- B. vsc.get_index()
- C. vsc.create_direct_access_index()
- D. vsc.similarity_search()
Answer: A
Explanation:
* Context: The Generative AI Engineer is setting up a vector store using Databricks' VectorSearchClient. This is typically done to enable fast and efficient retrieval of vectorized data for tasks like similarity searches.
* Explanation of Options:
Option A: vsc.get_index(): This function would be used to retrieve an existing index, not create one, so it would not be the logical next step immediately after creating an endpoint.
Option B: vsc.create_delta_sync_index(): After setting up a vector store endpoint, creating an index is necessary to start populating and organizing the data. The create_delta_sync_index() function specifically creates an index that synchronizes with a Delta table, allowing automatic updates as the data changes. This is likely the most appropriate choice if the engineer plans to use dynamic data that is updated over time.
Option C: vsc.create_direct_access_index(): This function would create an index that directly accesses the data without synchronization. While also a valid approach, it's less likely to be the next logical step if the default setup (typically accommodating changes) is intended.
Option D: vsc.similarity_search(): This function would be used to perform searches on an existing index; however, an index needs to be created and populated with data before any search can be conducted.
Given the typical workflow in setting up a vector store, the next step after creating an endpoint is to establish an index, particularly one that synchronizes with ongoing data updates, hence Option B.
NEW QUESTION # 30
A Generative AI Engineer is testing a simple prompt template in LangChain using the code below, but is getting an error.
Assuming the API key was properly defined, what change does the Generative AI Engineer need to make to fix their chain?
- A.

- B.

- C.

- D.

Answer: C
Explanation:
To fix the error in the LangChain code provided for using a simple prompt template, the correct approach is Option C. Here's a detailed breakdown of why Option C is the right choice and how it addresses the issue:
* Proper Initialization: In Option C, the LLMChain is correctly initialized with the LLM instance specified as OpenAI(), which likely represents a language model (like GPT) from OpenAI. This is crucial as it specifies which model to use for generating responses.
* Correct Use of Classes and Methods:
* The PromptTemplate is defined with the correct format, specifying that adjective is a variable within the template. This allows dynamic insertion of values into the template when generating text.
* The prompt variable is properly linked with the PromptTemplate, and the final template string is passed correctly.
* The LLMChain correctly references the prompt and the initialized OpenAI() instance, ensuring that the template and the model are properly linked for generating output.
Why Other Options Are Incorrect:
* Option A: Misuses the parameter passing in generate method by incorrectly structuring the dictionary.
* Option B: Incorrectly uses prompt.format method which does not exist in the context of LLMChain and PromptTemplate configuration, resulting in potential errors.
* Option D: Incorrect order and setup in the initialization parameters for LLMChain, which would likely lead to a failure in recognizing the correct configuration for prompt and LLM usage.
Thus, Option C is correct because it ensures that the LangChain components are correctly set up and integrated, adhering to proper syntax and logical flow required by LangChain's architecture. This setup avoids common pitfalls such as type errors or method misuses, which are evident in other options.
NEW QUESTION # 31
A Generative AI Engineer I using the code below to test setting up a vector store:
Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
- A. vsc.create_delta_sync_index()
- B. vsc.get_index()
- C. vsc.create_direct_access_index()
- D. vsc.similarity_search()
Answer: A
Explanation:
Context: The Generative AI Engineer is setting up a vector store using Databricks' VectorSearchClient. This is typically done to enable fast and efficient retrieval of vectorized data for tasks like similarity searches.
Explanation of Options:
* Option A: vsc.get_index(): This function would be used to retrieve an existing index, not create one, so it would not be the logical next step immediately after creating an endpoint.
* Option B: vsc.create_delta_sync_index(): After setting up a vector store endpoint, creating an index is necessary to start populating and organizing the data. The create_delta_sync_index() function specifically creates an index that synchronizes with a Delta table, allowing automatic updates as the data changes. This is likely the most appropriate choice if the engineer plans to use dynamic data that is updated over time.
* Option C: vsc.create_direct_access_index(): This function would create an index that directly accesses the data without synchronization. While also a valid approach, it's less likely to be the next logical step if the default setup (typically accommodating changes) is intended.
* Option D: vsc.similarity_search(): This function would be used to perform searches on an existing index; however, an index needs to be created and populated with data before any search can be conducted.
Given the typical workflow in setting up a vector store, the next step after creating an endpoint is to establish an index, particularly one that synchronizes with ongoing data updates, henceOption B.
NEW QUESTION # 32
A Generative Al Engineer is developing a RAG application and would like to experiment with different embedding models to improve the application performance.
Which strategy for picking an embedding model should they choose?
- A. Pick the most recent and most performant open LLM released at the time
- B. pick the embedding model ranked highest on the Massive Text Embedding Benchmark (MTEB) leaderboard hosted by HuggingFace
- C. Pick an embedding model trained on related domain knowledge
- D. Pick an embedding model with multilingual support to support potential multilingual user questions
Answer: C
Explanation:
The task involves improving a Retrieval-Augmented Generation (RAG) application's performance by experimenting with embedding models. The choice of embedding model impacts retrieval accuracy, which is critical for RAG systems. Let's evaluate the options based on Databricks Generative AI Engineer best practices.
Option A: Pick an embedding model trained on related domain knowledge
Embedding models trained on domain-specific data (e.g., industry-specific corpora) produce vectors that better capture the semantics of the application's context, improving retrieval relevance. For RAG, this is a key strategy to enhance performance.
Databricks Reference: "For optimal retrieval in RAG systems, select embedding models aligned with the domain of your data" ("Building LLM Applications with Databricks," 2023).
Option B: Pick the most recent and most performant open LLM released at the time LLMs are not embedding models; they generate text, not embeddings for retrieval. While recent LLMs may be performant for generation, this doesn't address the embedding step in RAG. This option misunderstands the component being selected.
Databricks Reference: Embedding models and LLMs are distinct in RAG workflows: "Embedding models convert text to vectors, while LLMs generate responses" ("Generative AI Cookbook").
Option C: Pick the embedding model ranked highest on the Massive Text Embedding Benchmark (MTEB) leaderboard hosted by HuggingFace The MTEB leaderboard ranks models across general tasks, but high overall performance doesn't guarantee suitability for a specific domain. A top-ranked model might excel in generic contexts but underperform on the engineer's unique data.
Databricks Reference: General performance is less critical than domain fit: "Benchmark rankings provide a starting point, but domain-specific evaluation is recommended" ("Databricks Generative AI Engineer Guide").
Option D: Pick an embedding model with multilingual support to support potential multilingual user questions Multilingual support is useful only if the application explicitly requires it. Without evidence of multilingual needs, this adds complexity without guaranteed performance gains for the current use case.
Databricks Reference: "Choose features like multilingual support based on application requirements" ("Building LLM-Powered Applications").
Conclusion: Option A is the best strategy because it prioritizes domain relevance, directly improving retrieval accuracy in a RAG system-aligning with Databricks' emphasis on tailoring models to specific use cases.
NEW QUESTION # 33
A Generative Al Engineer is working with a retail company that wants to enhance its customer experience by automatically handling common customer inquiries. They are working on an LLM-powered Al solution that should improve response times while maintaining a personalized interaction. They want to define the appropriate input and LLM task to do this.
Which input/output pair will do this?
- A. Input: Customer reviews; Output Group the reviews by users and aggregate per-user average rating, then respond
- B. Input: Customer reviews: Output Classify review sentiment
- C. Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary
- D. Input: Customer service chat logs; Output Group the chat logs by users, followed by summarizing each user's interactions, then respond
Answer: C
Explanation:
The task described in the question involves enhancing customer experience by automatically handling common customer inquiries using an LLM-powered AI solution. This requires the system to process input data (customer inquiries) and generate personalized, relevant responses efficiently. Let's evaluate the options step-by-step in the context of Databricks Generative AI Engineer principles, which emphasize leveraging LLMs for tasks like question answering, summarization, and retrieval-augmented generation (RAG).
Option A: Input: Customer reviews; Output: Group the reviews by users and aggregate per-user average rating, then respond This option focuses on analyzing customer reviews to compute average ratings per user. While this might be useful for sentiment analysis or user profiling, it does not directly address the goal of handling common customer inquiries or improving response times for personalized interactions. Customer reviews are typically feedback data, not real-time inquiries requiring immediate responses.
Databricks Reference: Databricks documentation on LLMs (e.g., "Building LLM Applications with Databricks") emphasizes that LLMs excel at tasks like question answering and conversational responses, not just aggregation or statistical analysis of reviews.
Option B: Input: Customer service chat logs; Output: Group the chat logs by users, followed by summarizing each user's interactions, then respond This option uses chat logs as input, which aligns with customer service scenarios. However, the output-grouping by users and summarizing interactions-focuses on user-specific summaries rather than directly addressing inquiries. While summarization is an LLM capability, this approach lacks the specificity of finding answers to common questions, which is central to the problem.
Databricks Reference: Per Databricks' "Generative AI Cookbook," LLMs can summarize text, but for customer service, the emphasis is on retrieval and response generation (e.g., RAG workflows) rather than user interaction summaries alone.
Option C: Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary This option uses chat logs (real customer inquiries) as input and tasks the LLM with identifying answers to similar questions, then providing a summarized response. This directly aligns with the goal of handling common inquiries efficiently while maintaining personalization (by referencing past interactions or similar cases). It leverages LLM capabilities like semantic search, retrieval, and response generation, which are core to Databricks' LLM workflows.
Databricks Reference: From Databricks documentation ("Building LLM-Powered Applications," 2023), an exact extract states: "For customer support use cases, LLMs can be used to retrieve relevant answers from historical data like chat logs and generate concise, contextually appropriate responses." This matches Option C's approach of finding answers and summarizing them.
Option D: Input: Customer reviews; Output: Classify review sentiment
This option focuses on sentiment classification of reviews, which is a valid LLM task but unrelated to handling customer inquiries or improving response times in a conversational context. It's more suited for feedback analysis than real-time customer service.
Databricks Reference: Databricks' "Generative AI Engineer Guide" notes that sentiment analysis is a common LLM task, but it's not highlighted for real-time conversational applications like customer support.
Conclusion: Option C is the best fit because it uses relevant input (chat logs) and defines an LLM task (finding answers and summarizing) that meets the requirements of improving response times and maintaining personalized interaction. This aligns with Databricks' recommended practices for LLM-powered customer service solutions, such as retrieval-augmented generation (RAG) workflows.
NEW QUESTION # 34
A Generative AI Engineer is developing an LLM application that users can use to generate personalized birthday poems based on their names.
Which technique would be most effective in safeguarding the application, given the potential for malicious user inputs?
- A. Implement a safety filter that detects any harmful inputs and ask the LLM to respond that it is unable to assist
- B. Ask the LLM to remind the user that the input is malicious but continue the conversation with the user
- C. Increase the amount of compute that powers the LLM to process input faster
- D. Reduce the time that the users can interact with the LLM
Answer: A
Explanation:
In this case, the Generative AI Engineer is developing an application to generate personalized birthday poems, but there's a need to safeguard againstmalicious user inputs. The best solution is to implement asafety filter (option A) to detect harmful or inappropriate inputs.
* Safety Filter Implementation:Safety filters are essential for screening user input and preventing inappropriate content from being processed by the LLM. These filters can scan inputs for harmful language, offensive terms, or malicious content and intervene before the prompt is passed to the LLM.
* Graceful Handling of Harmful Inputs:Once the safety filter detects harmful content, the system can provide a message to the user, such as "I'm unable to assist with this request," instead of processing or responding to malicious input. This protects the system from generating harmful content and ensures a controlled interaction environment.
* Why Other Options Are Less Suitable:
* B (Reduce Interaction Time): Reducing the interaction time won't prevent malicious inputs from being entered.
* C (Continue the Conversation): While it's possible to acknowledge malicious input, it is not safe to continue the conversation with harmful content. This could lead to legal or reputational risks.
* D (Increase Compute Power): Adding more compute doesn't address the issue of harmful content and would only speed up processing without resolving safety concerns.
Therefore, implementing asafety filterthat blocks harmful inputs is the most effective technique for safeguarding the application.
NEW QUESTION # 35
A Generative AI Engineer is tasked with deploying an application that takes advantage of a custom MLflow Pyfunc model to return some interim results.
How should they configure the endpoint to pass the secrets and credentials?
- A. Pass variables using the Databricks Feature Store API
- B. Pass the secrets in plain text
- C. Add credentials using environment variables
- D. Use spark.conf.set ()
Answer: C
Explanation:
Context: Deploying an application that uses an MLflow Pyfunc model involves managing sensitive information such as secrets and credentials securely.
Explanation of Options:
* Option A: Use spark.conf.set(): While this method can pass configurations within Spark jobs, using it for secrets is not recommended because it may expose them in logs or Spark UI.
* Option B: Pass variables using the Databricks Feature Store API: The Feature Store API is designed for managing features for machine learning, not for handling secrets or credentials.
* Option C: Add credentials using environment variables: This is a common practice for managing credentials in a secure manner, as environment variables can be accessed securely by applications without exposing them in the codebase.
* Option D: Pass the secrets in plain text: This is highly insecure and not recommended, as it exposes sensitive information directly in the code.
Therefore,Option Cis the best method for securely passing secrets and credentials to an application, protecting them from exposure.
NEW QUESTION # 36
A Generative Al Engineer is ready to deploy an LLM application written using Foundation Model APIs. They want to follow security best practices for production scenarios Which authentication method should they choose?
- A. Use an access token belonging to any workspace user
- B. Use OAuth machine-to-machine authentication
- C. Use an access token belonging to service principals
- D. Use a frequently rotated access token belonging to either a workspace user or a service principal
Answer: C
Explanation:
The task is to deploy an LLM application using Foundation Model APIs in a production environment while adhering to security best practices. Authentication is critical for securing access to Databricks resources, such as the Foundation Model API. Let's evaluate the options based on Databricks' security guidelines for production scenarios.
Option A: Use an access token belonging to service principals
Service principals are non-human identities designed for automated workflows and applications in Databricks. Using an access token tied to a service principal ensures that the authentication is scoped to the application, follows least-privilege principles (via role-based access control), and avoids reliance on individual user credentials. This is a security best practice for production deployments.
Databricks Reference: "For production applications, use service principals with access tokens to authenticate securely, avoiding user-specific credentials" ("Databricks Security Best Practices," 2023). Additionally, the "Foundation Model API Documentation" states: "Service principal tokens are recommended for programmatic access to Foundation Model APIs." Option B: Use a frequently rotated access token belonging to either a workspace user or a service principal Frequent rotation enhances security by limiting token exposure, but tying the token to a workspace user introduces risks (e.g., user account changes, broader permissions). Including both user and service principal options dilutes the focus on application-specific security, making this less ideal than a service-principal-only approach. It also adds operational overhead without clear benefits over Option A.
Databricks Reference: "While token rotation is a good practice, service principals are preferred over user accounts for application authentication" ("Managing Tokens in Databricks," 2023).
Option C: Use OAuth machine-to-machine authentication
OAuth M2M (e.g., client credentials flow) is a secure method for application-to-service communication, often using service principals under the hood. However, Databricks' Foundation Model API primarily supports personal access tokens (PATs) or service principal tokens over full OAuth flows for simplicity in production setups. OAuth M2M adds complexity (e.g., managing refresh tokens) without a clear advantage in this context.
Databricks Reference: "OAuth is supported in Databricks, but service principal tokens are simpler and sufficient for most API-based workloads" ("Databricks Authentication Guide," 2023).
Option D: Use an access token belonging to any workspace user
Using a user's access token ties the application to an individual's identity, violating security best practices. It risks exposure if the user leaves, changes roles, or has overly broad permissions, and it's not scalable or auditable for production.
Databricks Reference: "Avoid using personal user tokens for production applications due to security and governance concerns" ("Databricks Security Best Practices," 2023).
Conclusion: Option A is the best choice, as it uses a service principal's access token, aligning with Databricks' security best practices for production LLM applications. It ensures secure, application-specific authentication with minimal complexity, as explicitly recommended for Foundation Model API deployments.
NEW QUESTION # 37
A Generative AI Engineer at a legal firm is designing a RAG system to analyze historical legal cases. The system needs to process millions of court opinions and legal documents, already organized by time and topic, to track how interpretations of specific laws have evolved over time. All of these documents are in plain-text. The engineer needs to choose a chunking method that would most effectively preserve continuity and the temporal nature of the cases. Which method do they choose?
- A. Implement sentence level embeddings with each chunk tagged with the time to enable metadata filtering.
- B. Implement paragraph level embeddings with each chunk.
- C. Implement windowed summarization with overlapping chunks.
- D. Implement a hierarchical tree structure, like RAPTOR, to group similar legal concepts.
Answer: C
Explanation:
In the context of legal document analysis where the "evolution of interpretation" is the primary goal, preserving narrative continuity is paramount. Windowed summarization with overlapping chunks is the most effective method for this use case. Overlapping (e.g., 10-15% of the chunk size) ensures that sentences or concepts split at the boundary of one chunk are preserved in the next, preventing the loss of critical context that often occurs in legal jargon. Furthermore, windowed summarization allows the system to condense long-form court opinions into manageable parts while maintaining the chronological "thread" of the argument. While sentence-level embeddings with metadata (D) are useful for filtering, they often lack the sufficient context required to understand the nuances of a legal ruling. A windowed approach provides the LLM with enough surrounding text to understand the "why" behind a legal evolution, rather than just the "when."
NEW QUESTION # 38
A Generative Al Engineer is responsible for developing a chatbot to enable their company's internal HelpDesk Call Center team to more quickly find related tickets and provide resolution. While creating the GenAI application work breakdown tasks for this project, they realize they need to start planning which data sources (either Unity Catalog volume or Delta table) they could choose for this application. They have collected several candidate data sources for consideration:
call_rep_history: a Delta table with primary keys representative_id, call_id. This table is maintained to calculate representatives' call resolution from fields call_duration and call start_time.
transcript Volume: a Unity Catalog Volume of all recordings as a *.wav files, but also a text transcript as *.txt files.
call_cust_history: a Delta table with primary keys customer_id, cal1_id. This table is maintained to calculate how much internal customers use the HelpDesk to make sure that the charge back model is consistent with actual service use.
call_detail: a Delta table that includes a snapshot of all call details updated hourly. It includes root_cause and resolution fields, but those fields may be empty for calls that are still active.
maintenance_schedule - a Delta table that includes a listing of both HelpDesk application outages as well as planned upcoming maintenance downtimes.
They need sources that could add context to best identify ticket root cause and resolution.
Which TWO sources do that? (Choose two.)
- A. call_rep_history
- B. call_cust_history
- C. maintenance_schedule
- D. call_detail
- E. transcript Volume
Answer: D,E
Explanation:
In the context of developing a chatbot for a company's internal HelpDesk Call Center, the key is to select data sources that provide the most contextual and detailed information about the issues being addressed. This includes identifying the root cause and suggesting resolutions. The two most appropriate sources from the list are:
* Call Detail (Option D):
* Contents: This Delta table includes a snapshot of all call details updated hourly, featuring essential fields like root_cause and resolution.
* Relevance: The inclusion of root_cause and resolution fields makes this source particularly valuable, as it directly contains the information necessary to understand and resolve the issues discussed in the calls. Even if some records are incomplete, the data provided is crucial for a chatbot aimed at speeding up resolution identification.
* Transcript Volume (Option E):
* Contents: This Unity Catalog Volume contains recordings in .wav format and text transcripts in .txt files.
* Relevance: The text transcripts of call recordings can provide in-depth context that the chatbot can analyze to understand the nuances of each issue. The chatbot can use natural language processing techniques to extract themes, identify problems, and suggest resolutions based on previous similar interactions documented in the transcripts.
Why Other Options Are Less Suitable:
* A (Call Cust History): While it provides insights into customer interactions with the HelpDesk, it focuses more on the usage metrics rather than the content of the calls or the issues discussed.
* B (Maintenance Schedule): This data is useful for understanding when services may not be available but does not contribute directly to resolving user issues or identifying root causes.
* C (Call Rep History): Though it offers data on call durations and start times, which could help in assessing performance, it lacks direct information on the issues being resolved.
Therefore, Call Detail and Transcript Volume are the most relevant data sources for a chatbot designed to assist with identifying and resolving issues in a HelpDesk Call Center setting, as they provide direct and contextual information related to customer issues.
NEW QUESTION # 39
A Generative Al Engineer is developing a RAG application and would like to experiment with different embedding models to improve the application performance.
Which strategy for picking an embedding model should they choose?
- A. Pick the most recent and most performant open LLM released at the time
- B. pick the embedding model ranked highest on the Massive Text Embedding Benchmark (MTEB) leaderboard hosted by HuggingFace
- C. Pick an embedding model trained on related domain knowledge
- D. Pick an embedding model with multilingual support to support potential multilingual user questions
Answer: C
Explanation:
The task involves improving a Retrieval-Augmented Generation (RAG) application's performance by experimenting with embedding models. The choice of embedding model impacts retrieval accuracy,which is critical for RAG systems. Let's evaluate the options based on Databricks Generative AI Engineer best practices.
* Option A: Pick an embedding model trained on related domain knowledge
* Embedding models trained on domain-specific data (e.g., industry-specific corpora) produce vectors that better capture the semantics of the application's context, improving retrieval relevance. For RAG, this is a key strategy to enhance performance.
* Databricks Reference:"For optimal retrieval in RAG systems, select embedding models aligned with the domain of your data"("Building LLM Applications with Databricks," 2023).
* Option B: Pick the most recent and most performant open LLM released at the time
* LLMs are not embedding models; they generate text, not embeddings for retrieval. While recent LLMs may be performant for generation, this doesn't address the embedding step in RAG. This option misunderstands the component being selected.
* Databricks Reference: Embedding models and LLMs are distinct in RAG workflows:
"Embedding models convert text to vectors, while LLMs generate responses"("Generative AI Cookbook").
* Option C: Pick the embedding model ranked highest on the Massive Text Embedding Benchmark (MTEB) leaderboard hosted by HuggingFace
* The MTEB leaderboard ranks models across general tasks, but high overall performance doesn't guarantee suitability for a specific domain. A top-ranked model might excel in generic contexts but underperform on the engineer's unique data.
* Databricks Reference: General performance is less critical than domain fit:"Benchmark rankings provide a starting point, but domain-specific evaluation is recommended"("Databricks Generative AI Engineer Guide").
* Option D: Pick an embedding model with multilingual support to support potential multilingual user questions
* Multilingual support is useful only if the application explicitly requires it. Without evidence of multilingual needs, this adds complexity without guaranteed performance gains for the current use case.
* Databricks Reference:"Choose features like multilingual support based on application requirements"("Building LLM-Powered Applications").
Conclusion: Option A is the best strategy because it prioritizes domain relevance, directly improving retrieval accuracy in a RAG system-aligning with Databricks' emphasis on tailoring models to specific use cases.
NEW QUESTION # 40
A Generative AI Engineer is experimenting with using parameters to configure an agent in Mosaic Agent Framework. However, they are struggling to get the agent to respond with relevant information with this configuration:
config = {"prompt_template": "You are a trivia bot. Generate a question based on the user's input: {user_input}", "input_vars": ["user_input"], "parameters": {"temperature": 0.01, "max_tokens": 500}} Which error is causing the problem?
- A. The prompt does not parse the user's input vars
- B. The prompt does not set the retriever schema
- C. The prompt does not list available agents for the LLM to call
- D. The prompt is not wrapped in ChatModel
Answer: A
Explanation:
In the Mosaic AI Agent Framework and underlying LangChain-based configurations, the "input_vars" or "input_variables" must be correctly mapped and referenced within the template. If the configuration dictionary identifies user_input as the variable but the logic executing the chain does not correctly "inject" the runtime value into the {user_input} placeholder, the LLM will receive a literal string (or an empty value) rather than the user's actual question. This results in the model failing to provide relevant information because it essentially doesn't know what the user asked. Engineering standards require ensuring that the key used in the input_vars list matches the key in the JSON payload sent to the model serving endpoint. If there is a mismatch or a failure to parse, the prompt remains static, leading to generic or irrelevant responses.
NEW QUESTION # 41
A Generative AI Engineer is building a RAG application that will rely on context retrieved from source documents that are currently in PDF format. These PDFs can contain both text and images. They want to develop a solution using the least amount of lines of code.
Which Python package should be used to extract the text from the source documents?
- A. beautifulsoup
- B. unstructured
- C. flask
- D. numpy
Answer: A
Explanation:
* Problem Context: The engineer needs to extract text from PDF documents, which may contain both text and images. The goal is to find a Python package that simplifies this task using the least amount of code.
* Explanation of Options:
* Option A: flask: Flask is a web framework for Python, not suitable for processing or extracting content from PDFs.
* Option B: beautifulsoup: Beautiful Soup is designed for parsing HTML and XML documents, not PDFs.
* Option C: unstructured: This Python package is specifically designed to work with unstructured data, including extracting text from PDFs. It provides functionalities to handle various types of content in documents with minimal coding, making it ideal for the task.
* Option D: numpy: Numpy is a powerful library for numerical computing in Python and does not provide any tools for text extraction from PDFs.
Given the requirement,Option C(unstructured) is the most appropriate as it directly addresses the need to efficiently extract text from PDF documents with minimal code.
NEW QUESTION # 42
A Generative Al Engineer is tasked with developing a RAG application that will help a small internal group of experts at their company answer specific questions, augmented by an internal knowledge base. They want the best possible quality in the answers, and neither latency nor throughput is a huge concern given that the user group is small and they're willing to wait for the best answer. The topics are sensitive in nature and the data is highly confidential and so, due to regulatory requirements, none of the information is allowed to be transmitted to third parties.
Which model meets all the Generative Al Engineer's needs in this situation?
- A. OpenAI GPT-4
- B. BGE-large
- C. Llama2-70B
- D. Dolly 1.5B
Answer: B
Explanation:
Problem Context: The Generative AI Engineer needs a model for a Retrieval-Augmented Generation (RAG) application that provides high-quality answers, where latency and throughput are not major concerns. The key factors areconfidentialityandsensitivityof the data, as well as the requirement for all processing to be confined to internal resources without external data transmission.
Explanation of Options:
* Option A: Dolly 1.5B: This model does not typically support RAG applications as it's more focused on image generation tasks.
* Option B: OpenAI GPT-4: While GPT-4 is powerful for generating responses, its standard deployment involves cloud-based processing, which could violate the confidentiality requirements due to external data transmission.
* Option C: BGE-large: The BGE (Big Green Engine) large model is a suitable choice if it is configured to operate on-premises or within a secure internal environment that meets regulatory requirements.
Assuming this setup, BGE-large can provide high-quality answers while ensuring that data is not transmitted to third parties, thus aligning with the project's sensitivity and confidentiality needs.
* Option D: Llama2-70B: Similar to GPT-4, unless specifically set up for on-premises use, it generally relies on cloud-based services, which might risk confidential data exposure.
Given the sensitivity and confidentiality concerns,BGE-largeis assumed to be configurable for secure internal use, making it the optimal choice for this scenario.
NEW QUESTION # 43
A Generative AI Engineer is creating an LLM-powered application that will need access to up-to-date news articles and stock prices.
The design requires the use of stock prices which are stored in Delta tables and finding the latest relevant news articles by searching the internet.
How should the Generative AI Engineer architect their LLM system?
- A. Query the Delta table for volatile stock prices and use an LLM to generate a search query to investigate potential causes of the stock volatility.
- B. Use an LLM to summarize the latest news articles and lookup stock tickers from the summaries to find stock prices.
- C. Create an agent with tools for SQL querying of Delta tables and web searching, provide retrieved values to an LLM for generation of response.
- D. Download and store news articles and stock price information in a vector store. Use a RAG architecture to retrieve and generate at runtime.
Answer: C
Explanation:
To build an LLM-powered system that accesses up-to-date news articles and stock prices, the best approach is to create an agent that has access to specific tools (option D).
Agent with SQL and Web Search Capabilities:
By using an agent-based architecture, the LLM can interact with external tools. The agent can query Delta tables (for up-to-date stock prices) via SQL and perform web searches to retrieve the latest news articles. This modular approach ensures the system can access both structured (stock prices) and unstructured (news) data sources dynamically.
Why This Approach Works:
SQL Queries for Stock Prices: Delta tables store stock prices, which the agent can query directly for the latest data.
Web Search for News: For news articles, the agent can generate search queries and retrieve the most relevant and recent articles, then pass them to the LLM for processing.
Why Other Options Are Less Suitable:
A (Summarizing News for Stock Prices): This convoluted approach would not ensure accuracy when retrieving stock prices, which are already structured and stored in Delta tables.
B (Stock Price Volatility Queries): While this could retrieve relevant information, it doesn't address how to obtain the most up-to-date news articles.
C (Vector Store): Storing news articles and stock prices in a vector store might not capture the real-time nature of stock data and news updates, as it relies on pre-existing data rather than dynamic querying.
Thus, using an agent with access to both SQL for querying stock prices and web search for retrieving news articles is the best approach for ensuring up-to-date and accurate responses.
NEW QUESTION # 44
A Generative Al Engineer has built an LLM-based system that will automatically translate user text between two languages. They now want to benchmark multiple LLM's on this task and pick the best one. They have an evaluation set with known high quality translation examples. They want to evaluate each LLM using the evaluation set with a performant metric.
Which metric should they choose for this evaluation?
- A. BLEU metric
- B. ROUGE metric
- C. NDCG metric
- D. RECALL metric
Answer: A
Explanation:
The task is to benchmark LLMs for text translation using an evaluation set with known high-quality examples, requiring a performant metric. Let's evaluate the options.
* Option A: ROUGE metric
* ROUGE (Recall-Oriented Understudy for Gisting Evaluation) measures overlap between generated and reference texts, primarily for summarization. It's less suited for translation, where precision and word order matter more.
* Databricks Reference:"ROUGE is commonly used for summarization, not translation evaluation"("Generative AI Cookbook," 2023).
* Option B: BLEU metric
* BLEU (Bilingual Evaluation Understudy) evaluates translation quality by comparing n-gram overlap with reference translations, accounting for precision and brevity. It's widely used, performant, and appropriate for this task.
* Databricks Reference:"BLEU is a standard metric for evaluating machine translation, balancing accuracy and efficiency"("Building LLM Applications with Databricks").
* Option C: NDCG metric
* NDCG (Normalized Discounted Cumulative Gain) assesses ranking quality, not text generation.
It's irrelevant for translation evaluation.
* Databricks Reference:"NDCG is suited for ranking tasks, not generative output scoring" ("Databricks Generative AI Engineer Guide").
* Option D: RECALL metric
* Recall measures retrieved relevant items but doesn't evaluate translation quality (e.g., fluency, correctness). It's incomplete for this use case.
* Databricks Reference: No specific extract, but recall alone lacks the granularity of BLEU for text generation tasks.
Conclusion: Option B (BLEU) is the best metric for translation evaluation, offering a performant and standard approach, as endorsed by Databricks' guidance on generative tasks.
NEW QUESTION # 45
A Generative Al Engineer is helping a cinema extend its website's chat bot to be able to respond to questions about specific showtimes for movies currently playing at their local theater. They already have the location of the user provided by location services to their agent, and a Delta table which is continually updated with the latest showtime information by location. They want to implement this new capability In their RAG application.
Which option will do this with the least effort and in the most performant way?
- A. Create a Feature Serving Endpoint from a FeatureSpec that references an online store synced from the Delta table. Query the Feature Serving Endpoint as part of the agent logic / tool implementation.
- B. Query the Delta table directly via a SQL query constructed from the user's input using a text-to-SQL LLM in the agent logic / tool
- C. Set up a task in Databricks Workflows to write the information in the Delta table periodically to an external database such as MySQL and query the information from there as part of the agent logic / tool implementation.
- D. implementation. Write the Delta table contents to a text column.then embed those texts using an embedding model and store these in the vector index Look up the information based on the embedding as part of the agent logic / tool implementation.
Answer: A
Explanation:
The task is to extend a cinema chatbot to provide movie showtime information using a RAG application, leveraging user location and a continuously updated Delta table, with minimal effort and high performance. Let's evaluate the options.
Option A: Create a Feature Serving Endpoint from a FeatureSpec that references an online store synced from the Delta table. Query the Feature Serving Endpoint as part of the agent logic / tool implementation Databricks Feature Serving provides low-latency access to real-time data from Delta tables via an online store. Syncing the Delta table to a Feature Serving Endpoint allows the chatbot to query showtimes efficiently, integrating seamlessly into the RAG agent's tool logic. This leverages Databricks' native infrastructure, minimizing effort and ensuring performance.
Databricks Reference: "Feature Serving Endpoints provide real-time access to Delta table data with low latency, ideal for production systems" ("Databricks Feature Engineering Guide," 2023).
Option B: Query the Delta table directly via a SQL query constructed from the user's input using a text-to-SQL LLM in the agent logic / tool Using a text-to-SQL LLM to generate queries adds complexity (e.g., ensuring accurate SQL generation) and latency (LLM inference + SQL execution). While feasible, it's less performant and requires more effort than a pre-built serving solution.
Databricks Reference: "Direct SQL queries are flexible but may introduce overhead in real-time applications" ("Building LLM Applications with Databricks").
Option C: Write the Delta table contents to a text column, then embed those texts using an embedding model and store these in the vector index. Look up the information based on the embedding as part of the agent logic / tool implementation Converting structured Delta table data (e.g., showtimes) into text, embedding it, and using vector search is inefficient for structured lookups. It's effort-intensive (preprocessing, embedding) and less precise than direct queries, undermining performance.
Databricks Reference: "Vector search excels for unstructured data, not structured tabular lookups" ("Databricks Vector Search Documentation").
Option D: Set up a task in Databricks Workflows to write the information in the Delta table periodically to an external database such as MySQL and query the information from there as part of the agent logic / tool implementation Exporting to an external database (e.g., MySQL) adds setup effort (workflow, external DB management) and latency (periodic updates vs. real-time). It's less performant and more complex than using Databricks' native tools.
Databricks Reference: "Avoid external systems when Delta tables provide real-time data natively" ("Databricks Workflows Guide").
Conclusion: Option A minimizes effort by using Databricks Feature Serving for real-time, low-latency access to the Delta table, ensuring high performance in a production-ready RAG chatbot.
NEW QUESTION # 46
......
Databricks Databricks-Generative-AI-Engineer-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
Databricks-Generative-AI-Engineer-Associate Exam Dumps - Free Demo & 365 Day Updates: https://troytec.itpassleader.com/Databricks/Databricks-Generative-AI-Engineer-Associate-dumps-pass-exam.html